Instance-Based Classifier
These classifiers do not build models but classify new records based on their similarity to the examples in the training set.
They are called lazy-diligent learners as opposed to impatient learners (rule-based, decision trees).
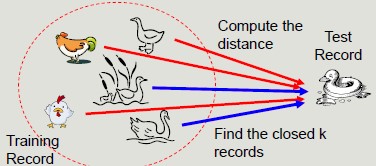
K-Nearest Neighbor
K-Nearest Neighbor is a simple algorithm that stores all the available cases and classifies the new data or case based on a similarity measure.
It is mostly used to classify a data point based on how its neighbors are classified.
Requirements:
- A training set
- A metric to calculate the distance between records
- The value of k (the number of neighbors to be used)
The classification process calculates the distance to the records in the training set, it identifies k nearest neighbors and uses nearest neighbor class labels to determine the class of the unknown record.
The choice of k is important because:
- If k is too small, the approach is sensitive to noise
- If k is too large, the surround may include examples belonging to other classes
Remember to normalize attributes in pre-processing, because to operate correctly, they should have the same scale of values.
Pros of KNN:
- Do not require the construction of a model
- Compared with rule-based or decision tree systems, they allow the construction of nonlinear class (more flexible)
Cons of KNN:
- Require a similarity or distance measure to assess closeness
- Require a pre-processing step to normalize the range of variation of attributes
- Class is locally determined and therefore susceptible to data noise
- Very sensitive to the presence of irrelevant or related attributes that will distort distances between objects
- Classification cost can be high and depends linearly on the size of the training set in the absence of appropriate index structures
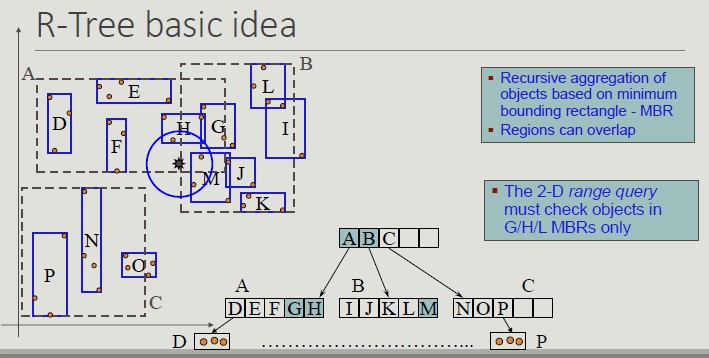
The R-Tree Index Structure
R-trees are extensions of B+-trees to multi-dimensional spaces:
- B+-trees organize objects into a set of non-overlapping one-dimensional intervals, applying this principle recursively from the leaves of the root
- R-trees organize objects into a set of overlapping multi-dimensional intervals, applying this principle recursively from the leaves to the root
Created: October 11, 2022 10:44:03