Data Preparation
Once obtained data for our Machine Learning system, it is necessary to prepare them.
They are organized as follows:
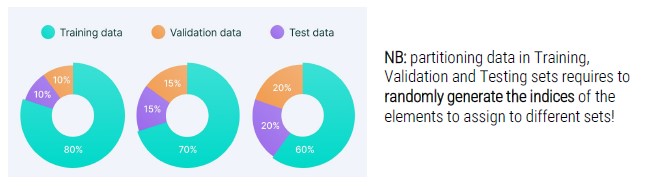
- Training set (data on which the model automatically learns during the learning phase)
- Validation set (part of the training set in which hyper-parameters are tuned)
- Training set (data on which the model is tested during testing phase in order to model effectiveness through qualitative and quantitative numerical measures)
Deployment
Once the previous phases have been completed, the ML system can be released for its effective use.
Normally, once the model is released, it no longer goes through training and testing phases.
Different ways to train-val-test
We can identify alternatives approaches adopted by choice or imposed by context:
- Batch: the training is carried out only once on a given training set.
- Incremental: following the initial training, further training sessions are possible
- Natural: this is the closest case ti the human learning process
Different Ways of Learning
Not all data is always annotated. Depending on whether they are annotated, we can define different types of learning:
- Annotated data -> Supervised Learning
- Not annotated data -> Unsupervised Learning
- Partially annotated data -> Semi-supervised Learning
Specific algorithms correspond to each of these areas. Usually, the presence of annotations helps and simplifies the development of ML algorithms. The best performances are usually obtained with supervised trained algorithms.
Created: October 12, 2022 13:15:00